a robozzle solver
Many years ago, a friend of mine showed me Robozzle and good times were had. Recently, I was looking for puzzles in the F-Droid store and Robozzle popped up. After doing a few dozen of them, like any good coder, I wondered: how easy would it be to automate this?
What is Robozzle, anyways?
In Robozzle, you play the part of an evil programmer who has to code the instructions for their robot to steal all the stars on a 16x12 board. Since you spent all your time in evil school instead of robot school, the robot doesn’t have many instructions: it can move forward, turn, draw a color on the board or call a routine. Each square of the board can be empty, red, blue or green. If the robot goes to an empty square, it falls off and perishes. Since the robot can recognize colors, it can be told to conditionally execute an instruction only on squares of a given color. The robot can also modify the board by coloring a square to a different color, which acts as a sort of “memory” for the robot.
An example program might be: F1: ^ R< F1 which means: go forward, turn left
on red squares and then call F1 again. Surprisingly, this small set of
instructions can do a lot of things.

How difficult is writing a solver?
The largest program that can be written consists of 5 tapes of 10 instructions.
So, given all of the above, how easy is it to write a program to solve a given
board configuration? A brute force program would essentially be: N**K where K
is the number of available operations. On a single colored board with one
routine, there might be only a handful instructions: forward, turn left, turn
right, call F1. However, on a three colored board, with 5 routines, the number
of instructions would be: (4 operations + 5 sub funcs + 3 write colors) * 3
colors = 36 potential instructions. This is noticeably harder to brute force.
In small experiments, brute force takes too long for 7 instructions on this
type of board.
A Random Algorithm
Instead of brute force, we can look for smarter alternatives. One popular category is randomized algorithms. What’s surprising about randomized algorithms is that they can actually do pretty well in exploring the solution space. For my robozzle solver, I wrote a genetic algorithm that evolves and mutates candidates until it finds one that solves the puzzle.
The genetic algorithm I used is reasonably simple, it has a few features:
Evolution: the algorithm starts by spawning random candidates. It then scores those candidates and picks the top 50, mutates them and scores the parents + their mutations and trims to the top 50 again. This is called a strain.
Fitness: the scoring of a candidate is based on 2 factors: what percentage of stars are collected + the percentage of squares visited. This rewards exploring more of the board. In order to reward exploration towards stars, each tile’s score is based on its travel distance from the nearest star.
Mutation: there are 3 types of mutations: 1) over-write random spots with new instructions, 2) randomly fill a subroutine and 3) randomly swap instructions. All 3 mutation types are run on a candidate and then inserted back into the pool.
Some additional changes to the genetic algorithm were added:
Generational: a strain is evolved for 100 iterations before moving to the next strain. after 10 strains are evolved, they are all mutated at once and the genetic algorithm is run on this megastrain for 500 iterations
Fertility: In a given iteration, the higher scoring children have more children. In this tuning, the top third get 3 copies of each mutation type, the middle get 2 and the last get 1.
In order to not completely fall into local maxima, two more additional features were added:
Spawning: Each iteration has an additional set of randomly spawned children added into it.
Charity: From the losers of each iteration, a random 10 programs are chosen for mutation and added into the next iteration.
Performance
Using python, this runs reasonably slowly so pypy was used. But even that is not enough, so a few optimizations were added:
- Pre-emptively trim a program that doesn’t have any forward instructions
- Detect loops and end early if we get stuck in an endless loop
- Don’t run a program for more than 2000 instructions
- Stop trying after 2 minutes and move on
Side Note: I wrote a brute force solver in c++ and pypy and surprisingly, the pypy was comparable in performance with generating all possible permutations. This had me wracking my head for a while - I still don’t understand what’s slow in the c++ version.
A better sort of randomness
Added on: February 4th
Around 7500 solved puzzles, the solver started hitting a wall. Thinking about what could be improved, a question I had was: “can we do better than pure randomness when selecting instructions?”. A program that has “write red”, “write red”, “write red” several times in a row is not actually that useful.
Wondering about how we can generate feasible programs and not just any program, I realized we can use markov chains for picking the instruction to place in a specific position.
Using the solutions from previously solved puzzles, we can generate probability distributions of which operations are likely to follow other operations. This concentrates the solutions that are generated, allowing the solver to go through more feasible programs in the same amount of time.
To gauge the difference, I ran the solver on the same puzzle 50 times and looked at the average solve time. With markov chains, the solve time averaged 4.7 seconds vs 7.3 seconds.
Using markov chains has shown the ability to solve more puzzles, but there are still at least a thousand unsolved puzzles. These puzzles tend to use stacks and the current solver fitness function seems to be having difficulties with them. A next area to explore is how to solve stack based puzzles in a better way.
Solving even more problems
Added on: February 10th
I received an email asking me for the source of robozzle. The email writer wanted a solver that could solve some pretty hard problems. After looking at the problems and what robozlov had been failing on, it was apparent that robozlov had difficulty with stack solutions.
It took a little experimenting to come up with a fitness metric that would help solve these problems, but after a couple days, it seems that one metric has helped a little bit. Now the fitness function is a combination of:
- stars collected / total stars
- squares visited / total sum of squares
- number of stack pops / total instructions executed
The new value, number of stack pops is essentially: how often do we exit a sub-routine. This was the best number I could come up with, but there might be a better one. If we had chosen, number of stack pushes, the solver would prioritize endless loops. We need a mechanism to reward using the stack - hence the stack pops.
With this modified solver, we can now a solve a few hundred more puzzles, but still haven’t been able to solve the originally requested puzzles.
Results
So how did the program do? After running it for ~3 days, it downloaded and solved 65.5% of the available puzzles on robozzle for a total of 6937 solved puzzles out of 10,579 total.
The first run solved ~6300 puzzles. I noticed that there was some improvements that could be made on loop detection and a second run yielded ~400 more solved puzzles - some likely by random chance and some because of the modified loop detection. A third run yielded ~200 more puzzles solved.
Jan 30th Update: The solver is now sitting at 70.5% success rate, with 7471 solved puzzles. Robozlov is sitting at 9th rank.
Feb 10th Update: The solver is now at 74.4% success rate, with 7922 puzzles solved. Robozlov is now sitting pretty at 5th rank
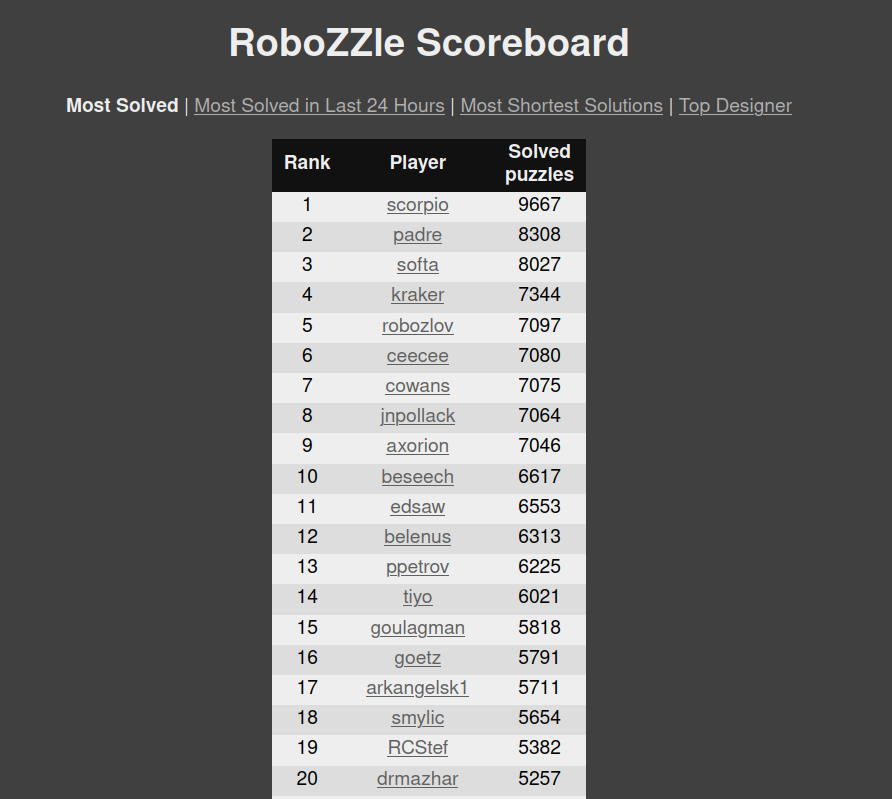
The scoreboard only counts puzzles that have a positive amount of likes
Comparison
Multiple other people have written robozzle solvers, but the best I’ve seen is zlejrob which has solved ~4500 puzzles as of January 2023 and is in rank 26 or 27 on the leaderboard. Tasuki wrote up their approach here
Other solvers I’ve seen are:
- Zolver: a brute force solver
- RobAI: an ML based solver
- robozzle.py: another brute forcer
How could it be improved?
- Modify the genetic algorithm to favor shorter solutions - currently the solutions always use the full puzzle length
- Look at puzzles that weren’t solved well and see if there are any insights as to why
- Currently, the evolution + generational iterations are hard-coded. It would be interesting to determine the “momentum” of a strain and keep improving it until we hit a wall
- Combine “similar” strains into one group: if we evolve a strain and it looks similar to a previous strain, we can probably merge them
- The solver tends to do poorly on solutions that have multiple functions of 10 instructions, these seem to make it stumble
- It’s not clear that the tile scoring function (distance from closest star) is the best scoring function for exploration. There could be a puzzle that requires moving away from the star first that this scoring would penalize.
- Analyze the “genealogy” of solutions and compare the frequency of a solution arriving during the normal strain evolution and megastrain evolution.
Closing Thoughts
This was a fun exercise over the last 2 weeks - I’ve been pleasantly surprised by the results. One thing that stuck out to me is how the terminology used affected the approach. Once genetic algorithm was chosen, the types of optimizations were influenced by the genetic metaphor. If I had chosen simulated annealing or a different evolutionary algorithm, maybe a different set of optimizations would have come out.